Bi-Level Off-policy Reinforcement Learning for Two-Timescale Volt/VAR Control in Active Distribution Networks
Abstract
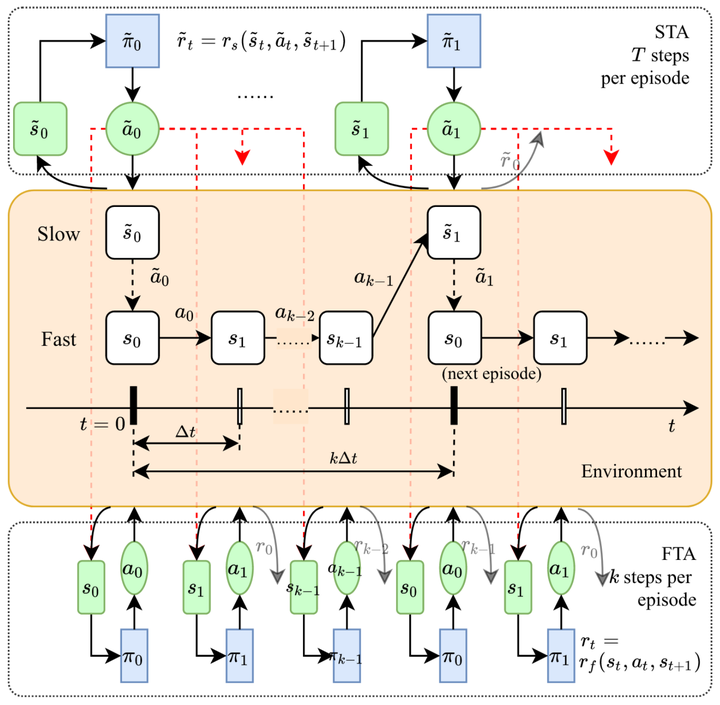
In Volt/Var control (VVC) of active distribution networks (ADNs), both slow timescale discrete devices (STDDs, e.g. on-load tap changers) and fast timescale continuous devices (FTCDs, e.g. distributed generators) are involved and should be coordinated in time sequence. Traditional two-timescale VVC optimizes STDDs and FTCDs based on accurate system models, but sometimes is impractical because of its unaffordable modelling effort. In this paper, a novel bi-level off-policy reinforcement learning (RL) method is proposed to solve this in a model-free manner. A Bi-level Markov decision process (BMDP) is defined and separate agents are set up for the slow and fast timescale sub-problems. For the fast timescale sub-problem, we adopt an off-policy RL method with high sample efficiency. For the slow one, we develop an off-policy multi-discrete soft actor-critic (MDSAC) algorithm to address the curse of dimensionality with various STDDs. To mitigate the non-stationary issue in the two agents' training, we propose a multi-timescale off-policy correction (MTOPC) method by adopting importance sampling technique. Comprehensive numerical studies not only demonstrate the proposed method can achieve stable and satisfactory optimization of both STDDs and FTCDs without any model information, but also support that the proposed method outperforms existing VVC methods involving both STDDs and FTCDs.
Haotian Liu
PhD of Electrical Engineering
My research interests include reinforcement learning, contextual bandit, power system and model-free control.